.jpg)
About this website
Welcome!
You’ve probably just landed here from the front page, or from another post where I’ve linked this as a reference on how to get around. Hello! This post serves as a high-level index of everything on this site, an explanation of how it all gets built, and a home for a few visualisations of the content on here.
High-level organisation
This site is a “digital garden”, something about halfway between a blog and a wiki. Just as organising a small patch of the real world is very fulfilling, so is cultivating a small patch of the internet. Writing about what I’m learning and organising all of this content is something I find really enjoyable, even if I’m ultimately just organising it for myself. But if anyone else finds anything useful or interesting, that’s great.
Broadly, this site is organised into a few main sections:
Each section has a different colour: orange, blue, green or purple.
Blog posts
I’ve written a few blog posts over the years and try to write a new one every other week. It’s hard to describe a general theme which unites all of them, but I think most of them would appeal to a Hacker News-type audience. Mostly I just write about what I’m finding interesting or am working on.
My favourite blog posts so far are:
- [[Number theory at the card table]]B: This is about a surprising connection between why some fractions have periodic decimal expansions (like sevenths), and why exactly 8 riffle shuffles will return a deck of 52 playing cards to their original order.
- [[Extending multidimensional integration in SciPy]]?: This is about some work I did in 2024 on SciPy, adding support for the adaptive cubature of multidimensional array-valued functions. This post is also available on the Quansight Labs blog.
- [[FRACTRAN and theoretically cheating at your A-levels]]B: This describes how you can fit a universal Turing machine into an A-level maths calculator using a very unconventional model of computation invented by John Conway.
- [[Winning colourful Nim with the eeny-meeny rule]]B: This post analyses a variant of Nim and describes a complete winning strategy.
I’m a big fan of a service called Beeminder, which allows you to create “commitment contracts”: do $X$ or get charged $£Y$. I’ve set one up which will charge me £5 if I don’t publish a blog post at least once every other week. I’ve also written a bit about using Beeminder for studying in [[Beeminding as a university student]]B.
Notes
The other main component of this site is a place for my notes from university and sixth form to live.
University notes
[[University Notes]]U contains all notes I’ve taken studying mathematics and computer science so far. These are mostly in the form of Anki flashcards for definitions, theorems and proofs. For example, take a look at:
- [[Course - Quantum Information HT24]]U (a high level entry organising all my notes for a second-year quantum computing course I took)
- [[Notes - Complex Analysis MT23, Jordan’s lemma]]U (a specific result in a second-year complex analysis which helps you evaluate contour integrals)
- [[Notes - ADS HT24, Approximation algorithms]]U (about approximation algorithms, which are one of the things you can turn to when faced with an NP-hard problem: they let you find efficiently find a solution which may not be optimal but is guaranteed to be within some factor of the optimum)
- [[Notes - DAA HT23, All the algorithms]]U (a list of all of the algorithms I thought were relevant for the first-year algorithms and data structures exam)
A-Level notes
[[A-Level Notes]]A contains all the notes that I took studying Maths, Physics, Further Maths and Computer Science at A-Level in sixth form. These are far less complete than my university notes, but are very similar in format. If you’re interested, take a look at:
- [[Further Maths - Syllabus]]A (a high level entry organising my notes for the subject Further Maths)
- [[Maths - Reciprocal Trig Functions]]A (a list of identities involving reciprocal trigonometric functions: secant, cosecant and cotangent).
- [[Computing - Finite State Machines]]A (about finite state machines, which are a limited abstract model of computation).
I really like seeing how going to university has “turned up the resolution” for my notes on lots of different topics. In my A-Level notes on finite state machines above, I have things like:
(A-Level): What is a finite state machine?
An abstract model of computation that is used to model logic.
but after taking [[Course - Models of Computation MT23]]U, I can have things like:
(University): Can you give the formal definition of a DFA?
A 5-tuple $(Q, \Sigma, \delta, q _ 0, F)$ where
- $Q$ is a finite set of states
- $\Sigma$ is a finite set called the “alphabet”
- $\delta : Q \times \Sigma \to Q$ is the transition function
- $q _ 0 \in Q$ is the start state
- $F \subseteq Q$ is the set of accepting states
For more detail on my note taking process, there’s some explanation in [[University Notes]]U. I am particularly happy with my notes for:
- [[Course - Algorithms and Data Structures HT24]]U
- [[Course - Metric Spaces MT23]]U
- [[Course - Complex Analysis MT23]]U
- [[Course - Analysis II HT23]]U
Personal notes
Alongside my university and A-Level notes, I also have notes on other things I have found interesting. These are mostly organised in the following entries:
-
[[Bookshelf]]N:
- The bookshelf is a list of almost every book I’ve read since 2020, with short notes on each of them. For example:
- [[Thinking, Fast and Slow, Kahneman]]N
- [[The Man Who Loved Only Numbers, Hoffman]]N
- [[Gödel, Escher, Bach]]N
- [[The MANIAC, Labatut]]N
-
[[Other Notes]]N:
- These are my other notes that don’t fit anywhere else. For example:
- [[Replacing Guilt, Soares]]N
- [[Meditations on Moloch, Alexander]]N
- [[AI - A Modern Approach]]N
Misc
[[Misc]]M holds all of the miscellaneous content that doesn’t really fit into one of the other categories. There’s not many pages like this, so I can list them all here:
How this site is made
This site and the notes on are built from a big mishmash from lots of great tools:
- Obsidian, a closed-source notes app.
- Building the site
-
obsidiantools, a Python library for interacting with Obsidian. - Jekyll, a static site generator written in Ruby.
-
al-folio, a very popular Jekyll theme.
-
- Flashcards
- Anki, an intelligent spaced-repetition flashcard program
Obsidian-Anki-Sync
Writing notes
I take all my notes in Obsidian, which is a closed source notes app. It’s a shame that it is closed-source, but it is free and is the best note taking app I have used. Unlike some alternatives like Joplin or Roam with store notes in arcane SQLite databases, Obsidian is just a skin over a folder of markdown files.
This means that for example my notes for year two of university ( [[Part A]]U) are just a folder on my computer (here only shown two levels deep):
.
├── Part A.md
├── exams
│ ├── list
│ ├── papers
│ └── questions-to-review
├── ht24
│ ├── ads
│ ├── courses
│ ├── gdp
│ ├── numerical-analysis
│ ├── quantum-information
│ └── rings-and-modules
└── mt23
├── complex-analysis
├── courses
├── linear-algebra
├── machine-learning
├── metric-spaces
└── models-of-computation
Why use a closed-source skin over a folder of markdown files rather than just editing the files in a text editor? I also did this for 2 years using Vim and a program I wrote called albatross, but the experience using Obsidian is considerably smoother since it natively handles things like displaying images and keeping track of the links between all the files. Doing all of this with a Vim took a lot of effort.
Since all my notes are just folders of markdown files, they are naturally organised into a tree structure like you can see above. But Obsidian also lets you create wikilinks, which are inter-note links [[enclosed in square brackets]] – this is what all of the colourful links are. This means that your notes are also organised into a (directed) graph where each node is a file, and two nodes are connected is there is a wikilink from one to the other.
The main way in which I take notes is by making flashcards. These look like this:
What is a flashcard?
A question-and-answer pair.
Like the rest of the site, these are also written entirely in Markdown, using syntax like
<-- flashcard -->
What is a flashcard?::
A question-and-answer-pair
<-- flashcard-end -->
Then there’s a plugin for Obsidian called Obsidian-Anki-Sync which will go through all my notes, parse these blocks, and sync them with Anki. Then every morning I’ll be given a list of flashcards to attempt, picked by Anki in a way it thinks is best for getting information into long term memory. This way I can memorise lots of important stuff that I’ll need to know in an exam.
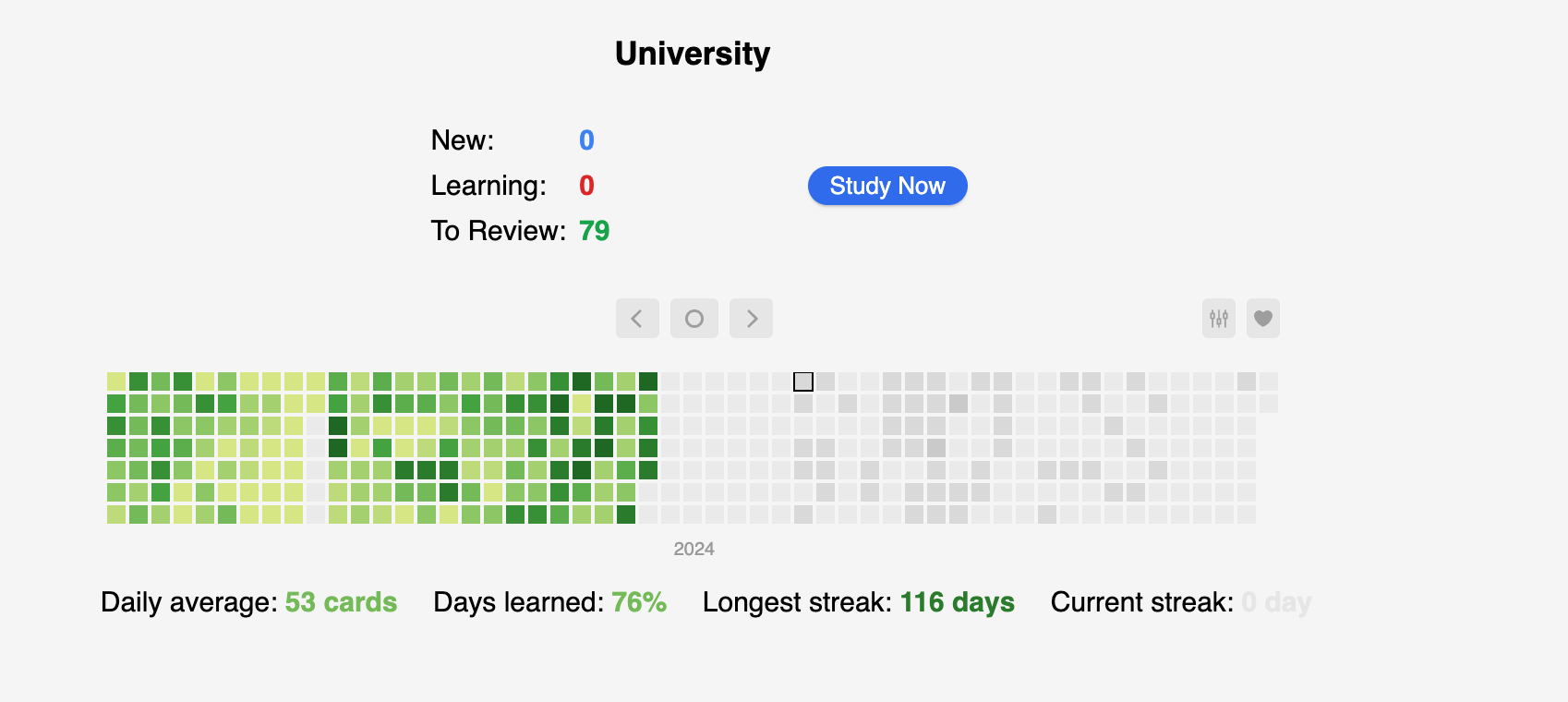
(this is what Anki looks like, each square is a day. The darker it is, the more cards I reviewed on that day).
I used to have the philosophy that flashcards should be super short and concise, and this view was spurred on by great essays like What are the most important attributes of good spaced repetition memory prompts? and Augmenting Long-term Memory. Over time, I’ve become less hardcore about this, now I might make a flashcard for a proof that takes about 10 minutes to complete so that I can learn it semi-rote using Anki. This isn’t really what Anki is used for, but it is useful for exams. The best solution might be a piece of software specifically designed for practicing proofs / questions, I tried something similar for A-levels with a project called Sergeant, but this isn’t perfect.
One more thing about flashcards: I think there’s a lot of value just in creating flashcards even if you never review them, since the process of just compressing and reformulating the information is very useful, especially if the source material is not great.
Like my notes, all blog posts and miscellaneous content is also just markdown files in certain directories on my computer.
Building the site
To actually convert all these files into a website, I use a popular static site generator written in Ruby called Jekyll. Jekyll builds static sites from folders of markdown files, which is great, but there’s quite a bit of processing that needs to be done so that Obsidian and Jekyll can work nicely with each other. This includes:
- Filtering out notes I don’t want to be included
- Being able to recognise
[[wikilinks]], which Jekyll doesn’t natively understand - Putting posts into categories
- Deciding on paths and titles
- Parsing flashcards so that they can be rendered nicely
- Performing special processing for things like the home page or [[Bookshelf]]N
- Calculating semantic embeddings for each post using the Sentence Transformers library
- …fixing some more very specific interoperability issues, like how underscores have to be escaped in Obsidian math blocks for them to render properly in Jekyll.
This is all done with a library called obsidiantools and a hacky Python program which will spit out a _posts folder Jekyll can convert into a site using the al-folio theme. There’s a few extra custom things done here like rendering flashcards and wikilinks, but the majority of the heavy lifting is done by Jekyll and al-folio.
Some pages also get special processing so that they have a different layout, like the homepage. Some of these pages are:
- [[About]]B
- [[Bookshelf]]N
- [[Genius At Play, Roberts]]N
- The page you’re currently on, for the visualisations in the next section
There’s also some secret data created in the form of JSON files, which lives at assets/data.
Serving the website
The site is hosted on a small OVH VPS and is served using Caddy.
Visualising all the content with machine learning
As part of the processing when this site is built, “embeddings” are calculated for each post using the Sentence Transformers library. This converts each post into a 384-dimensional vector which is a numerical representation of the underlying meaning of the text. This means that posts with similar embeddings (in the sense of cosine similarity) end up being semantically similar: e.g. the blog post [[Can you ever draw in 3D noughts and crosses?]]B is quite close to [[Lecture - Functional Programming MT22, XIII]]U, since that lecture was about implementing Countdown in Haskell, and both noughts & crosses and Countdown are games. This is what creates the “Related posts” section at the end of each page.
The fun part is that you can then project these 384-dimensional vectors into 3-dimensional space using a technique called principal component analysis. This visualisation does exactly that. If you look around, you might be able to spot interesting clusters of similar notes: one for analysis, one for algebra, one for blog posts, and so on.
Though not interactive, I’ve also done the same thing but where I’ve included all of my private notes. These notes are in black.
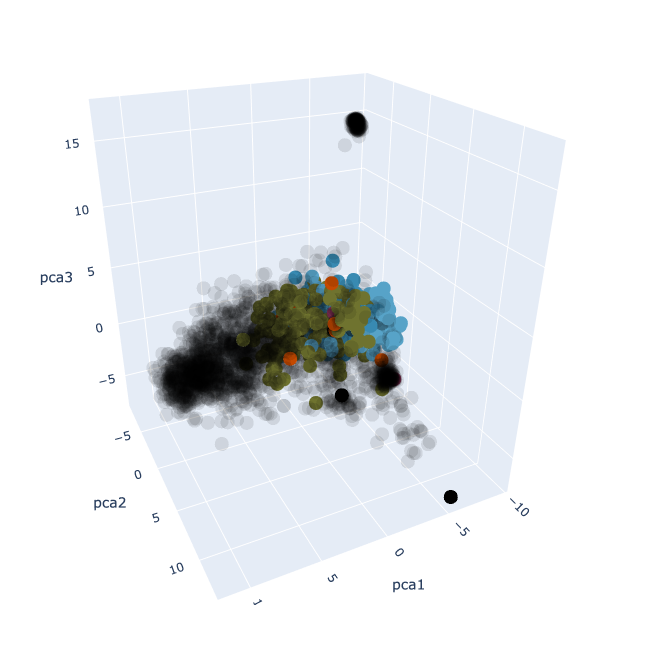
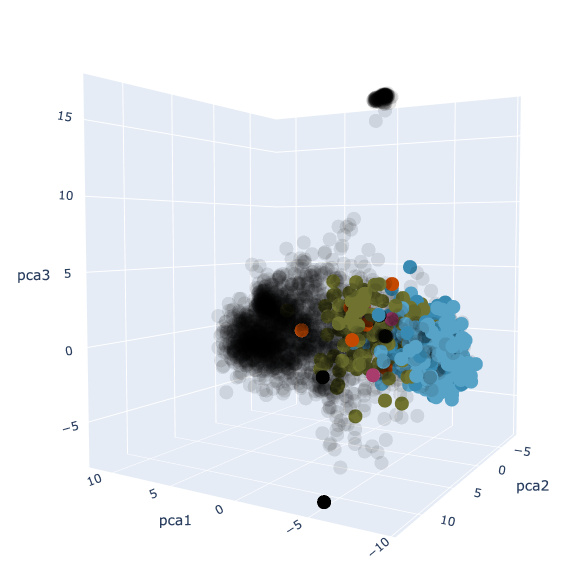
As a consequence of how PCA works (see [[Notes - Machine Learning MT23, Principal component analysis]]U if you’re interested), adding in my private notes will change the locations of all the existing points, so it won’t look the same as it does in the visualisation above.
Conclusion
I hope that was interesting and you have fun looking around!