Geometric Deep Learning HT26, Graphs
Flashcards
Basic definitions
@Define the difference between transductive and inductive tasks on graphs.
- In a transductive task, the graph is the same but the nodes may differ for each task
- In an inductive task, the graph can be completely different for each task
@State the desired property of functions acting on graphs.
They should be permutation invariant to the ordering of the nodes.
Suppose we have some function $f(\mathbf X, \mathbf A)$ operating on graph nodes and features. @Define what it means for $f$ to be permutation invariant and what it means to be permutation equivariant.
and
\[\mathbf F(\mathbf{PX}, \mathbf{PAP}^\top) = \mathbf{PF}(\mathbf X, \mathbf A)\]for any permutation matrix $\mathbf P$.
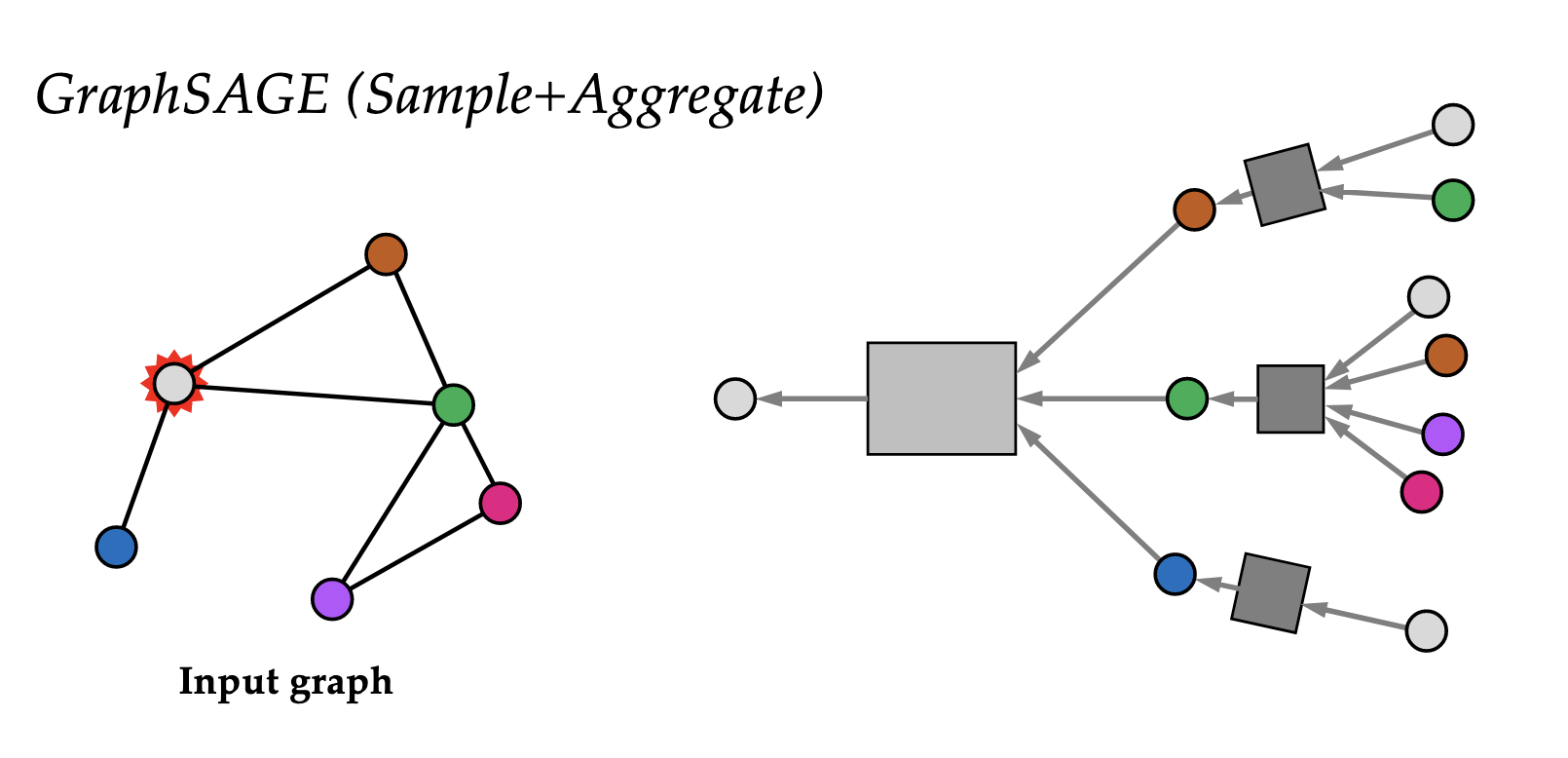
@State the general blueprint for constructing permutation equivariant functions on graphs, and visualise this procedure.
Define a local function $\phi$ that operates over a node and its neighbourhood, $\phi(\mathbf x _ u, \mathbf X _ {\mathcal N _ u})$. Then a permutation equivariant function $\mathbf F$ can be constructed by applying $\phi$ to every node’s neighbourhood in isolation, i.e.
\[F(\mathbf{X}, A) = \begin{bmatrix} \cdots \quad \phi(\mathbf{x} _ 1, \mathbf{X} _ {\mathcal{N} _ 1}) \quad \cdots \\ \cdots \quad\phi(\mathbf{x} _ 2, \mathbf{X} _ {\mathcal{N} _ 2}) \quad \cdots \\ \vdots \\ \cdots \quad\phi(\mathbf{x} _ n, \mathbf{X} _ {\mathcal{N} _ n}) \quad \cdots \end{bmatrix}\]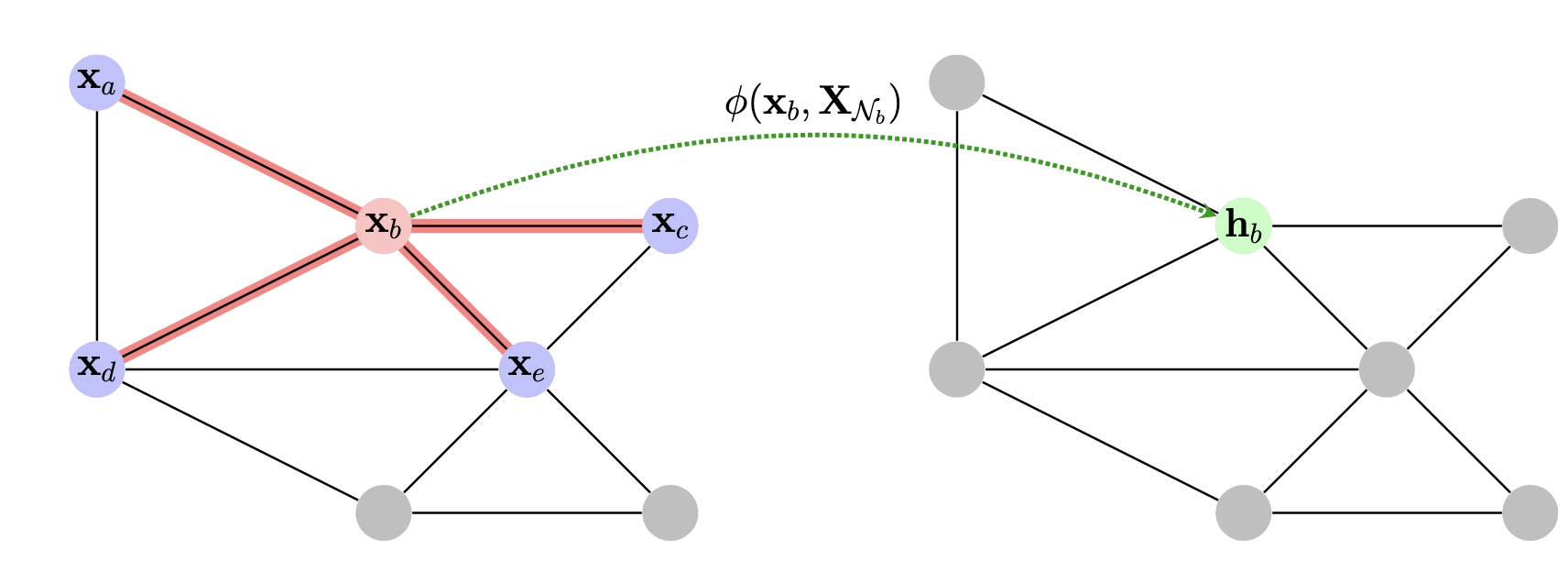
Graph neural networks
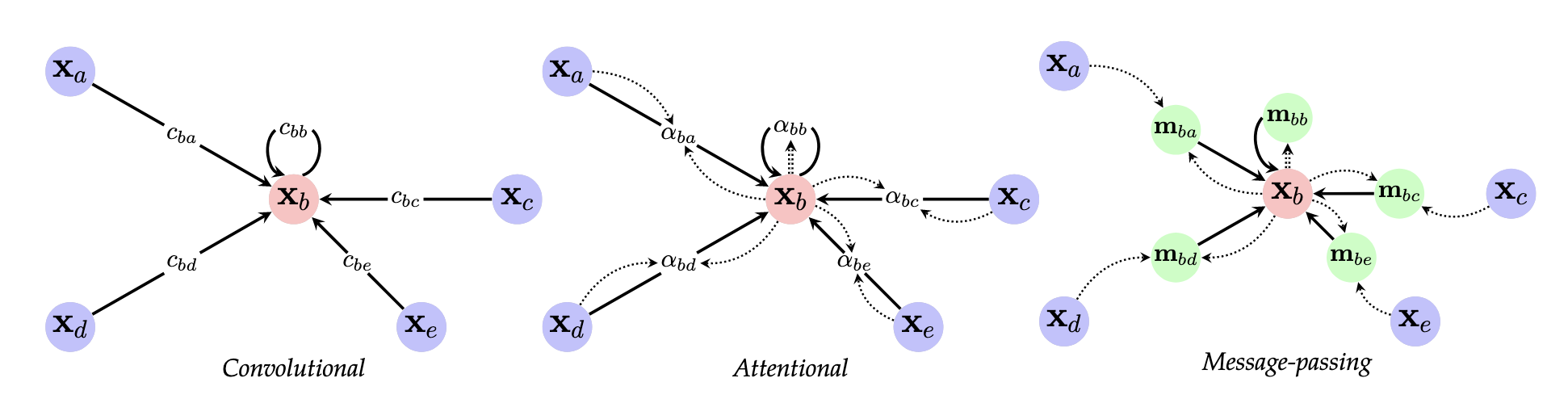
@Define and @visualise the three “flavours” of ways to aggregate information from surrounding nodes in a graph neural network.
Convolutional:
\[\mathbf h _ u = \phi\left( \mathbf x _ u, \bigoplus _ {v \in \mathcal N} c _ {uv} \psi(\mathbf x _ v) \right)\]where $c _ {uv}$ is a constant that depends only on the structure of the graph (i.e. the adjacency matrix), $\psi$ is a (potentially learned) function that transforms the features of the neighbourhood $\mathcal N$, $\bigoplus$ is some permutation-invariant aggregation function, and $\phi$ is some (learnable) function that updates these features.
Attentional:
\[\mathbf h _ u = \phi\left( \mathbf x _ u, \bigoplus _ {v \in \mathcal N _ u} a(\mathbf x _ u, \mathbf x _ v) \psi(\mathbf x _ v)\right)\]where $a$ is a learnable self-attention mechanism that computed the importance coefficients $\alpha _ {uv} = a(\mathbf x _ u, \mathbf x _ v)$ implicitly, and are often softmax-normalised across all neighbours.
Message-passing:
\[\mathbf h _ u = \phi\left(\mathbf x _ u, \bigoplus _ {v \in \mathcal N _ u} \psi(\mathbf x _ u, \mathbf x _ v) \right)\]where $\psi$ is a learnable message function, computing $v$’s vector sent to $U$.
@State the containments between the relative expressive power of GNNs implemented via:
- convolution
- attention
- message-passing
@State how a graph convolution neighbourhood averaging operation could be performed over a graph.
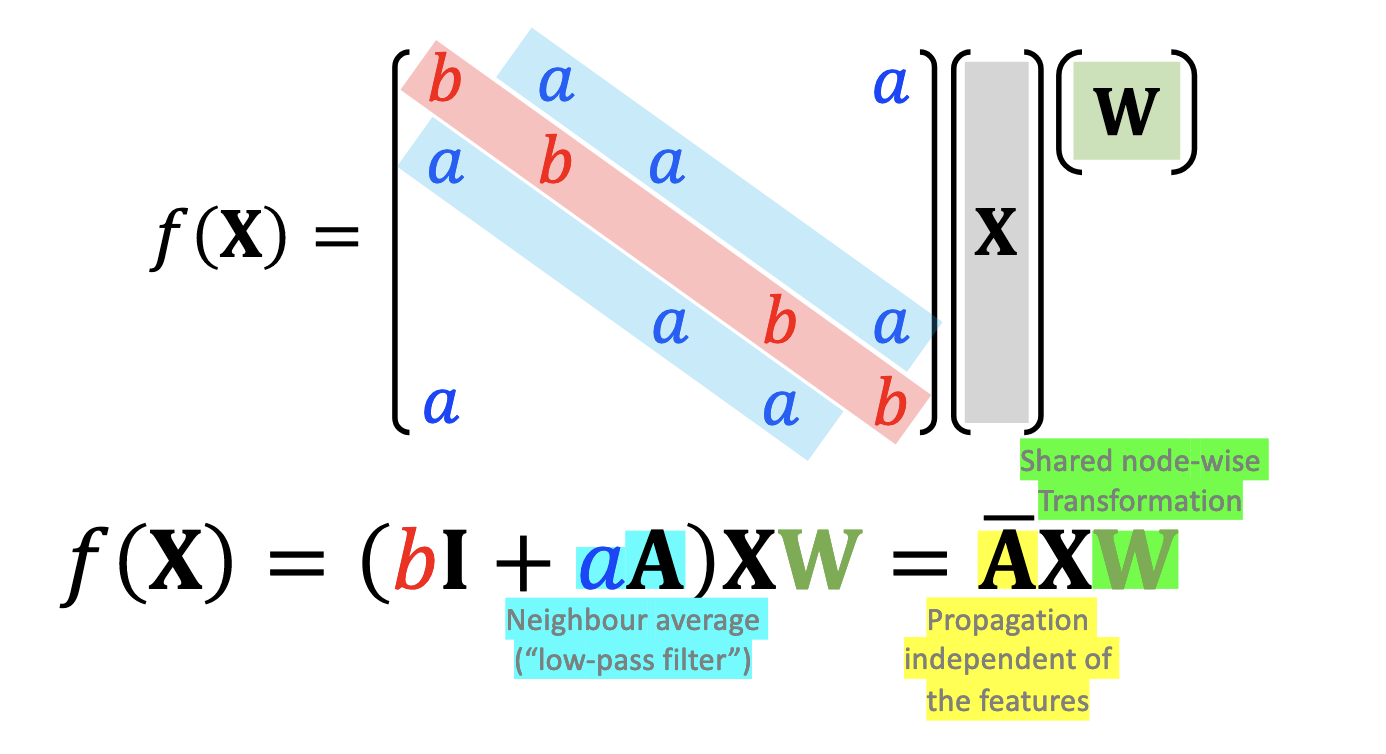
@Visualise one layer of a graph convolution network with softmax activation.
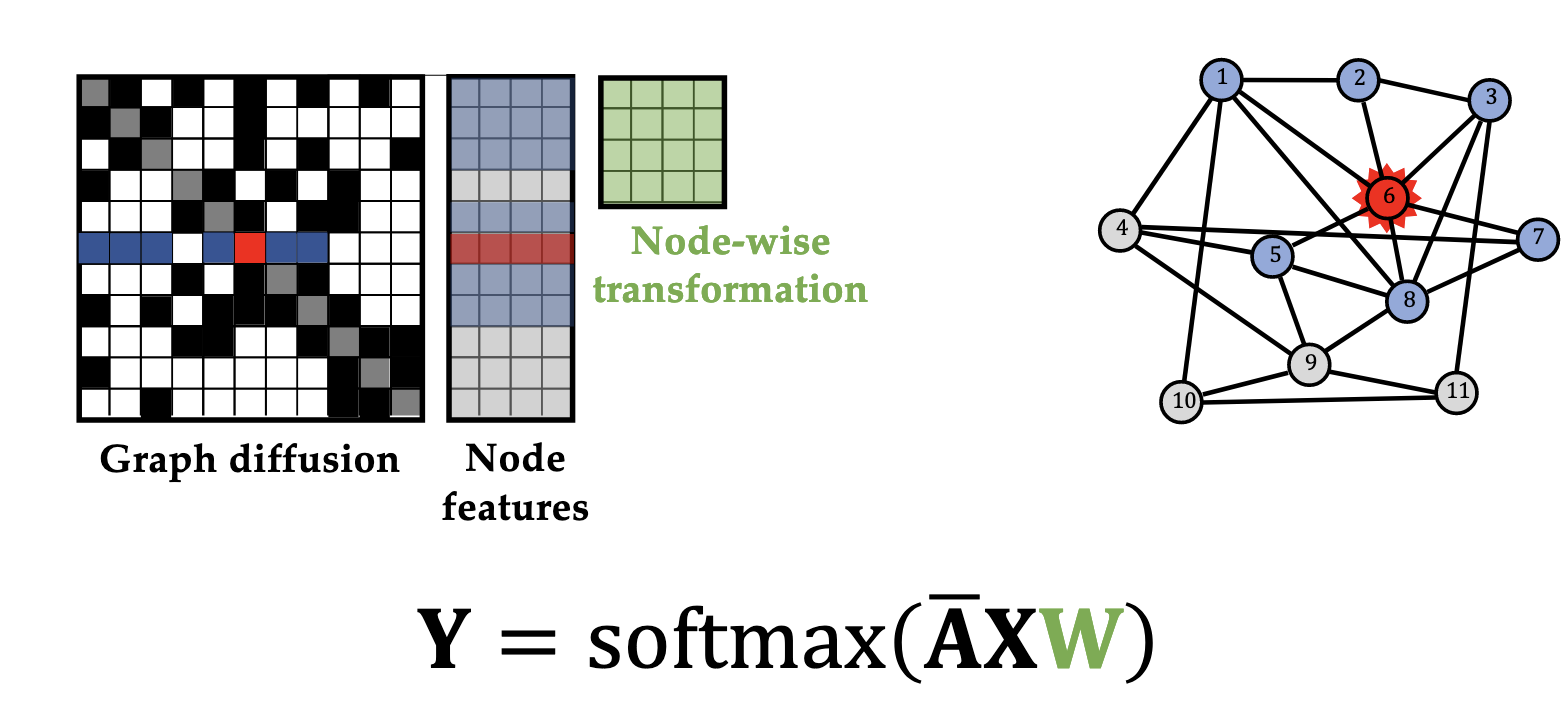
@Visualise a two-layer graph convolution network with activation $\sigma$ and final output $\text{softmax}$.
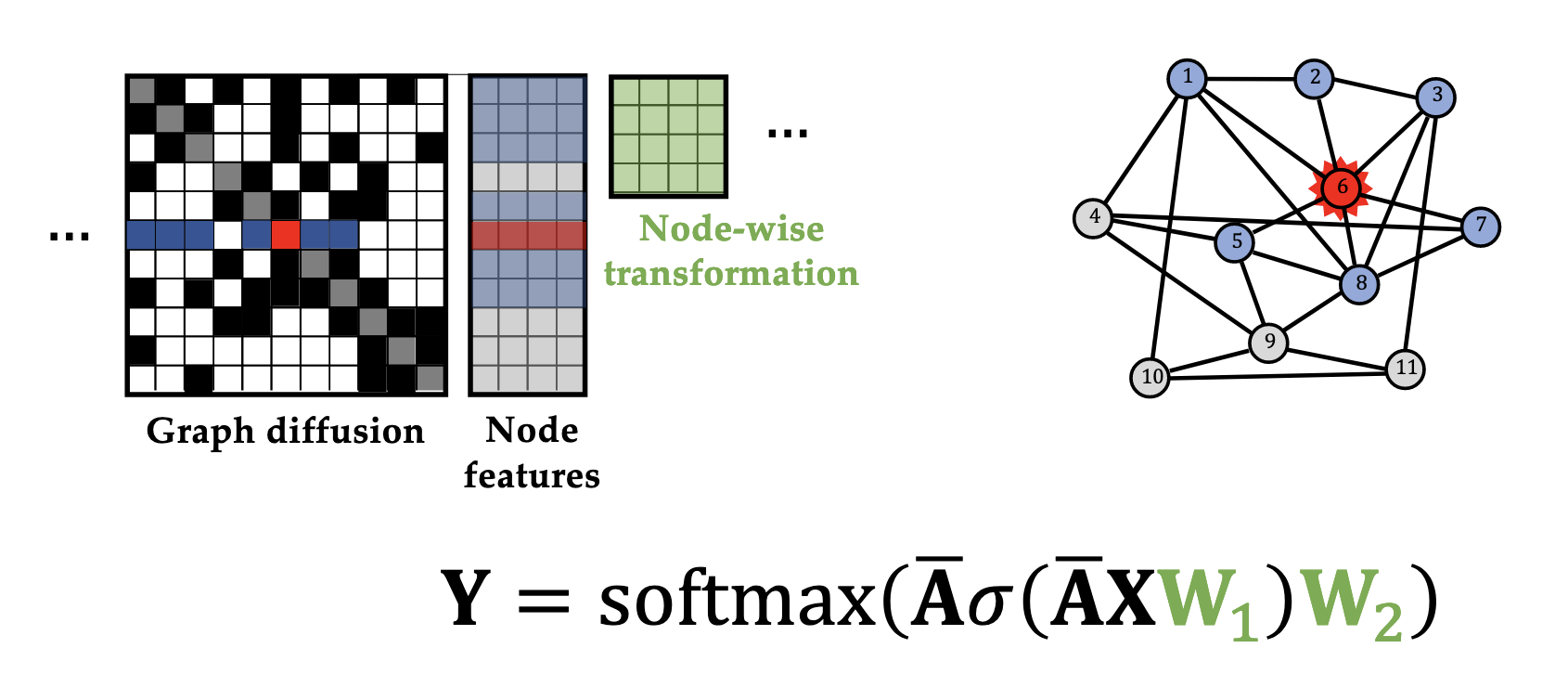
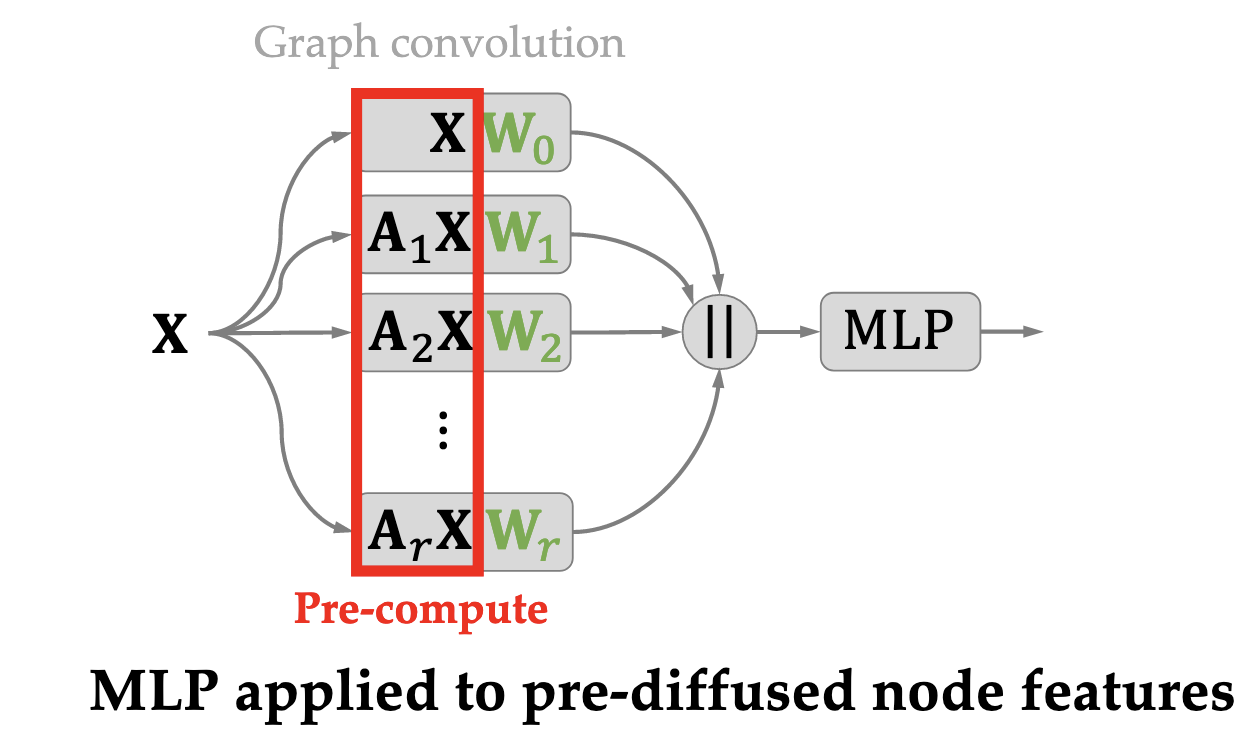
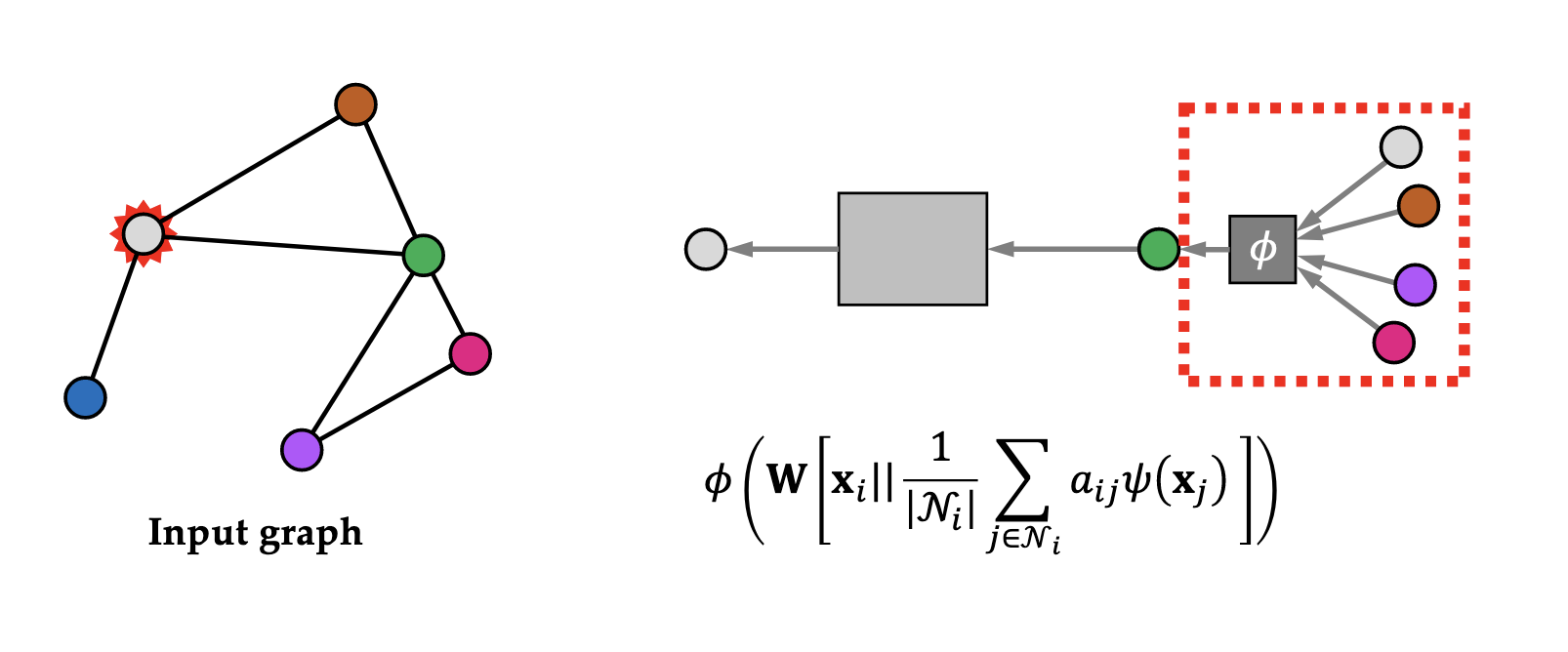
Expressivity
@Define what it means for two node-attributed graphs $G = (V, E, \mathbf X)$ and $G' = (V', E', \mathbf X')$ to be isomorphic.
There exists a bijection $\phi : V \to V'$ such that you have
- Structure preservation: $u \sim v$ in $G$ iff $\phi(u) \sim \phi(v)$ in $G'$
- Feature preservation: $\mathbf x _ u = \mathbf x' _ {\phi(u)}$
(i.e. they are isomorphic as graphs and features are preserved).
@State a theorem giving a condition for a class of functions to be able to universally approximate any permutation invariant function on graphs.
A class of functions is universally approximating permutation-invariant functions on graphs with finite node features iff it can discriminate graph isomorphisms.
@Visualise the containment between the expressive power of functions that can be computed by message-parsing neural networks and all permutation-invariant functions on graphs.

Weisfeiler-Lehman test
What is the Weisfeiler-Lehman test at a high level?
A necessary but insufficient condition for graph isomorphism, based on iterative colour refinement.
@Visualise the relative expressive powers of functions that can be computed by message-passing graph neural networks, those that can be computed by WL-test style functions, those that depend on the counts of certain substructures, and all permutation invariant functions.
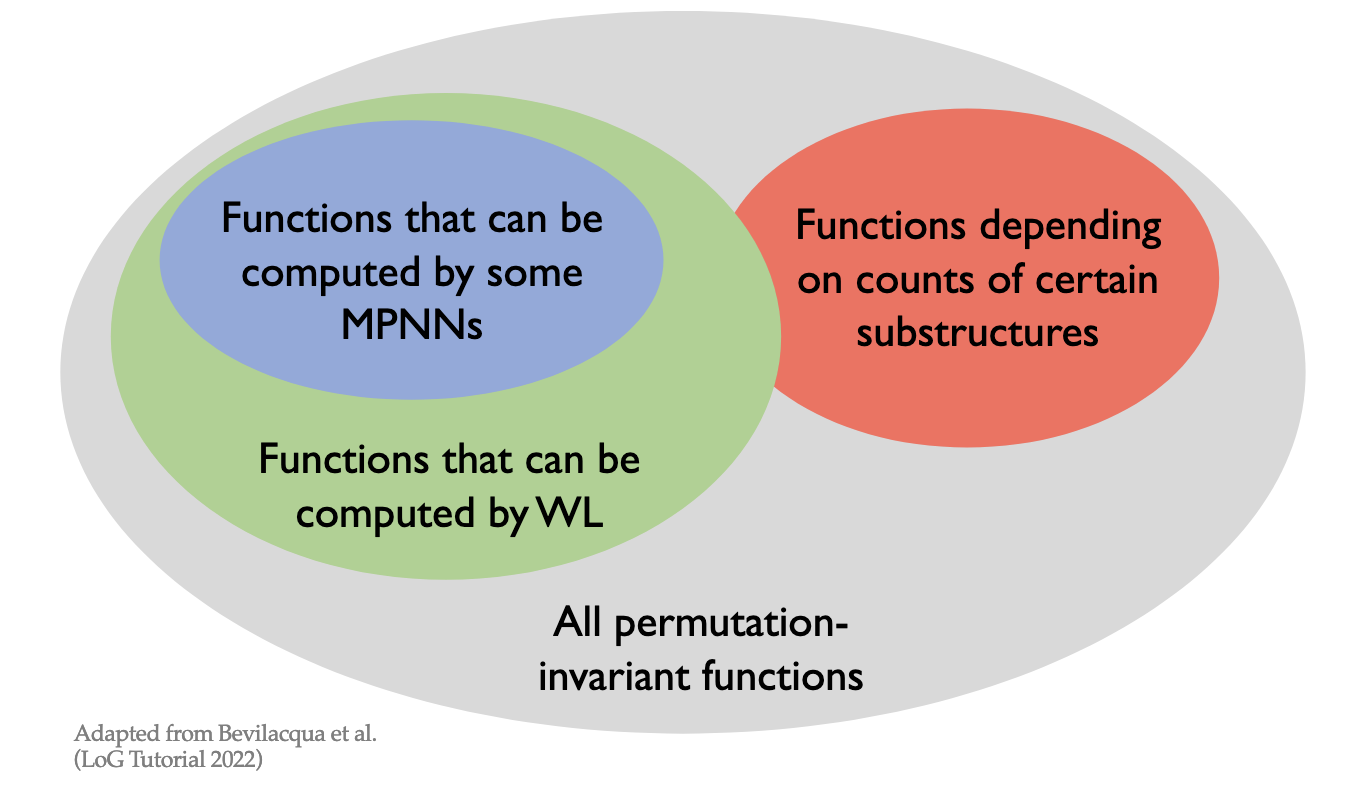
@State a theorem about the expressive power of a graph isomorphism network.
Suppose:
- Graph node features are from a discrete countable set (often not true in practice)
- We have an injective aggregator $\bigoplus$ and $\phi$
- The readout function is graph-wise
Then this MPNN is as powerful as the WL-test.
@State a theorem about the number of aggregators needed to distinguish between real multisets of size $n$.
At least $n$ aggregators are needed.
@Define principled neighbourhood aggregation.
An aggregation function defined as moments of neighbour features:
\[\bigoplus = \begin{bmatrix} I \\ S(D, \alpha = 1) \\ S(D, \alpha = -1) \end{bmatrix} \otimes \begin{bmatrix} \mu \\ \sigma _ {\max} \\ m _ {\min} \end{bmatrix}\]where we define scalers $S(d, \alpha)$ as
\[S(d, \alpha) = \left( \frac{\log(d+1)}{\delta} \right)^\alpha\]What are $k$-WL tests at a high-level?
Colour refinement over $k$-tuples, where two $k$-tuples are adjacent if they differ in one node.
What is the idea behind random node features and random message passing neural networks (rMPMMs)?
Attach a random feature to every node of the graph, then apply a MPNN. This is to break symmetries that would confuse the WL-test.
What is the idea behind a graph substructure networks (GSNs)?
Choose a bank of substructures containing graphs $H$ of size $k$, and count the occurence of each $H$ in every node or edge of the input graph.
@Visualise the class of graphs that GSNs can distinguish compared to $k$-WL tests.
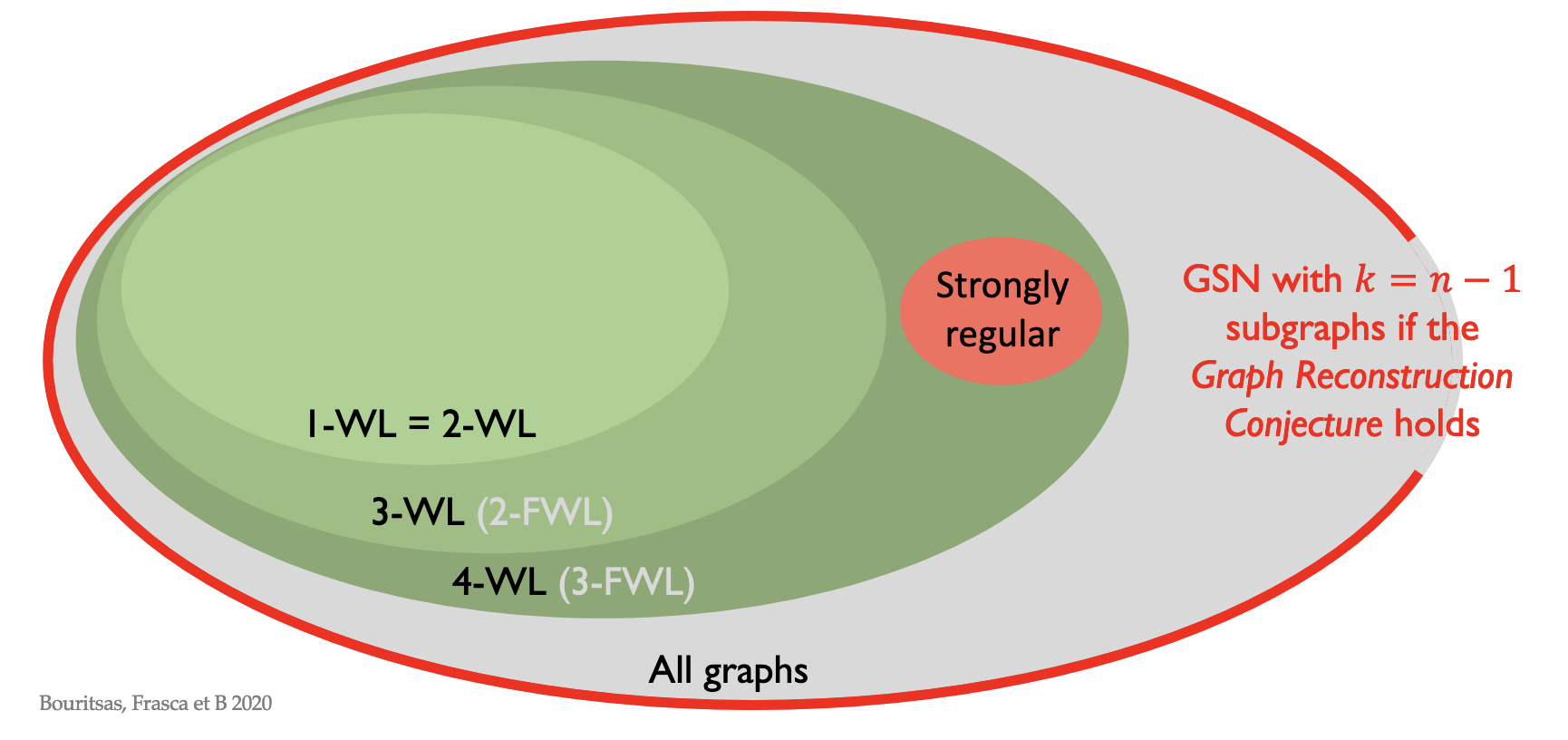
What is the idea behind subgraph GNNs?
Create a collection of subgraphs of the original graph by deleting edges. Then run a permutation-invariant network over the features generated by GNNs applied to each subgraph. This can distinguish graphs the WL-test cannot.
Transformers
How can you interpret transformers as a type of GNN?
Their architecture is equivalent to an attention GNN on a complete graph with positional encoding.
Over-squashing and bottlenecks
- Sometimes properties of the graph means that long-term interactions are not modelled way
- Capacity bounds
Exotic message passing
- Some more unusual ways of message passing