Computer Vision MT25, Convolutional neural networks
Flashcards
What was the “neocognitron”?
An early (1959) example of an image-processing neural network, trained layerwise using a method called “self-organising maps”.
What idea motivated CNNs?
They should be invariant to shifts, scale and small distortions.
What three properties of a CNN help make them learn to be invariant to shifts, scale and small distortions?
- Local weighted connections
- Shared weights across spatial locations
- Spatial subsampling
How are CNN architectures generally composed?
- Filters arranged with a width, height and depth
- Alternating convolutional and subsampling layers
- Fully connected layers at the end
What was maybe unnecessary about the filters used in LeNet?
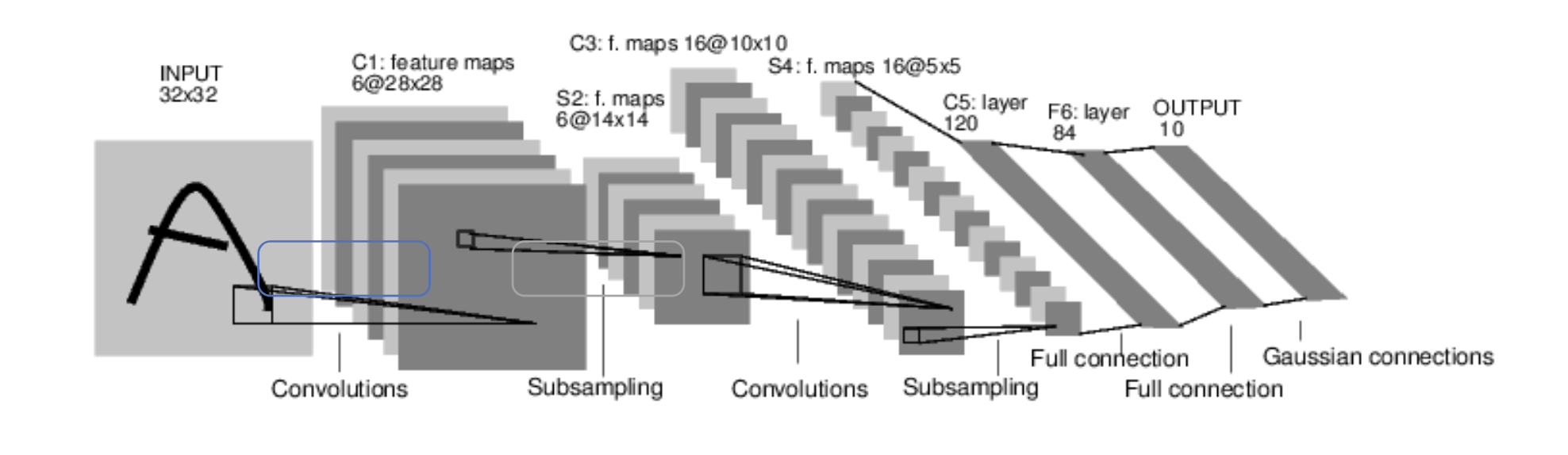
They were unnecessarily large, many later architectures used much smaller filters.
Suppose you have a convolutional filter of dimensions $h \times w \times d$. How much should you zero-pad the input?
Add $(h-1)/2$ cells to the top and bottom, and $(w-1)/2$ cells to the left and right.
Suppose you have a $10 \times 10 \times 3$ input volume, which you process by applying a $3 \times 3 \times 3$ convolutional filter. What is the size of the resulting output volume?
@example~
Suppose:
- You have an input volume of size $h _ \text{in} \times w _ \text{in} \times d$
- You have a convolutional filter of size $h \times w \times d$ (although $d$ being the same here is not necessary)
- The stride of this filter is $s$
@State the dimensions of the output.
where
\[\begin{aligned} h _ \text{out} &= \frac{h _ \text{in} - h + 2p}{s} + 1 \\ w _ \text{out} &= \frac{w _ \text{in} - w + 2p}{s} + 1 \end{aligned}\]What are the hyperparameters of a convolution layer in a CNN?
- The number of filters
- The width, height and depth of the filters
- The stride of each of the filters
- How padding is calculated
How is bias added in a convolutional layer of a CNN?
It is added to each output channel, so e.g. if after applying your filter you have a $3 \times 3$ output, you add the same scalar to each of the $3 \times 3$ entries.
Suppose:
- You have an input volume of size $h _ \text{in} \times w _ \text{in} \times d$
- You have a pooling layer of width $w$ and height $h$
- The stride is $s$
When does overlapping of the sliding window occur?
If $s < w$ or $s < h$.
Suppose:
- You have an input volume of size $h _ \text{in} \times w _ \text{in} \times d$
- You have a pooling layer of width $w$ and height $h$
- The stride is $s$
@State the dimensions of the output.
where
\[\begin{aligned} h _ \text{out} &= \frac{h _ \text{in} - h}{s} + 1 \\ w _ \text{out} &= \frac{w _ \text{in} - w}{s} + 1 \end{aligned}\]How can you interpret a fully connected layer as a convolutional layer?
Each filter has the same size as the input, so you can do an arbitrary linear combination of all the previous layers.
What differences did VGG make over LeNet?
- Smaller convolutions
- Deeper network
