Computer Vision MT25, Segmentation
Flashcards
In what way is image classification, object detection and segmentation all really the same task?
They are all instances of spatial labelling, at different levels of granularity:
- Image classification: Image-scale
- Object detection: Region-scale
- Segmentation: Pixel-scale
@Define semantic segmentation.
The task of labelling each pixel in an image with a category label, not differentiating instances.
What’s one way you could evaluate a segmentation model?
Do a per-class IoU of the predictions versus the ground truth.
How could you do segmentation with a sliding window approach?
Slide a window over the whole image and classify the centre pixel of the window.
What are the main drawbacks of sliding window segmentation?
- It is very inefficient: we are recomputing the same features for overlapping patches
- It is very noisy: separate predictions for each class
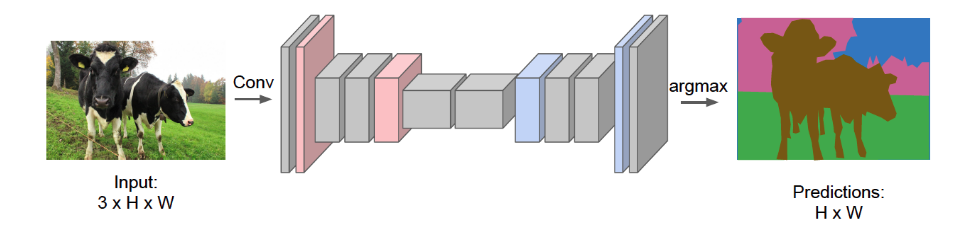
@Define and @visualise a fully convolutional network (FCN).
A CNN where you replace the final fully connected layers by convolutions and maintain the same input / output image size.
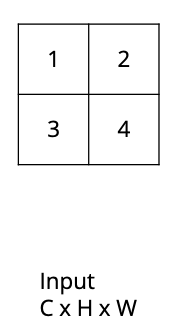
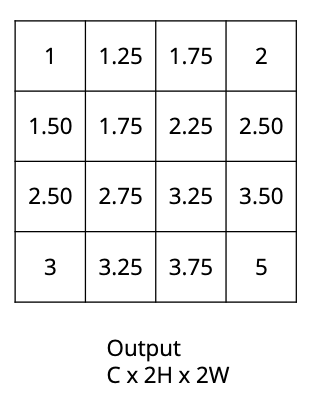
How would the nearest neighbour upsampling algorithm convert this $C \times H \times W$ image into a $C \times 2H \times 2W$ image?
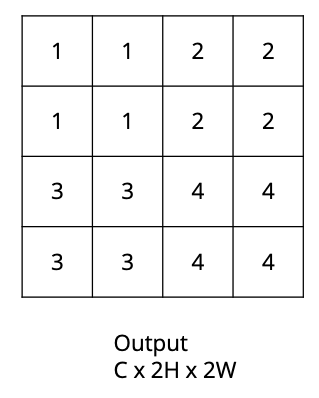
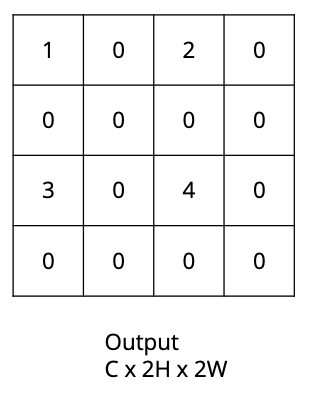
How would the bed of nails upsampling algorithm convert this $C \times H \times W$ image into a $C \times 2H \times 2W$ image?
How would the bilinear interpolation upsampling algorithm convert this $C \times H \times W$ image into a $C \times 2H \times 2W$ image?
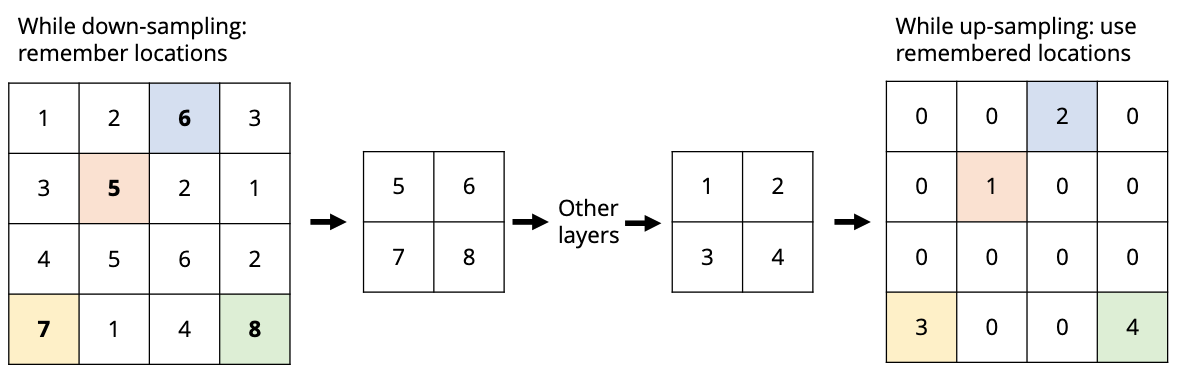
How would the max-unpooling upsampling algorithm convert this $C \times H \times W$ image into a $C \times 2H \times 2W$ image
given that this was down-sampled via
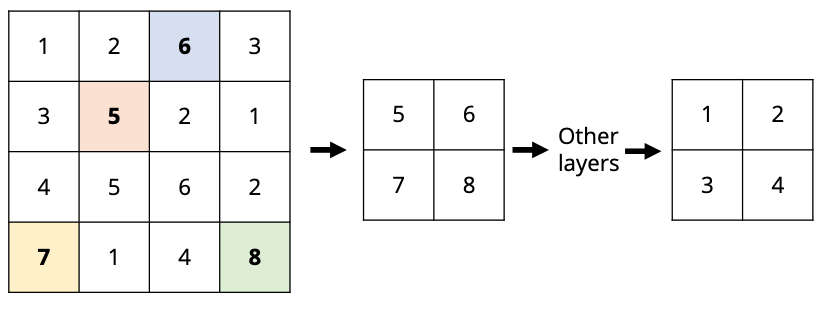
?
How would a transposed convolution (width, height 3 and stride 2) applied to the input square $a _ 1, a _ 2, a _ 3, a _ 4$ calculate the upsampled version?
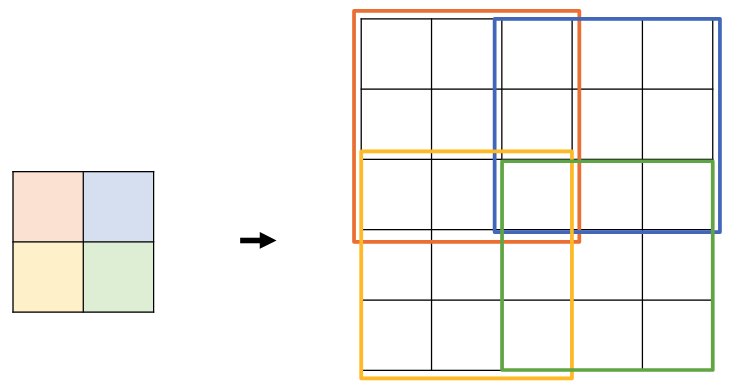
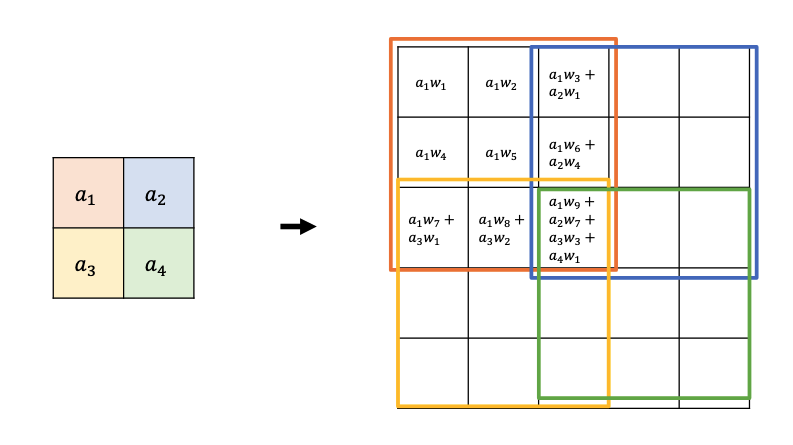
What artefacts do you typically get using transposed convolutions and how are these handled?
The repeated sums in the intersection points mean you get a grid-like pattern, you can fix this with another normal convolution.
What is the advantage of transposed convolutions compared to other upsampling techniques?
There are learnable weights.
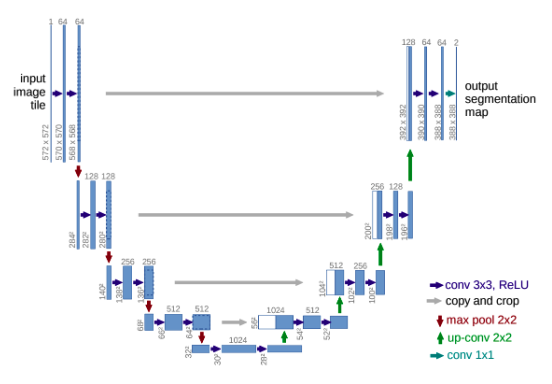
@Visualise a U-net and @describe two of its special features that made it particularly effective.
- Skip/residual connections
- Concatenating upsampled higher-level feature maps with higher-res, lower-level feature maps
@Describe the technique that the Segment Anything Model (SAM) used in order to gather such a large amount of supervised training data.
- Training with humans in the loop:
- Annotate data
- Train model
- Label more data with the model
- Humans fix and improve the labels
- Goto 2
@Define a thing.
An object with a specific size and shape.
@Define stuff.
Material defined by a homogeneous or repetitive pattern of fine-scale properties, but has no specific or distinctive spatial extent or shape.
@Define instance segmentation.
Detecting all objects (things) in an image, and identify the pixels that belong to each object.
@Visualise the difference between semantic segmentation and instance segmentation.
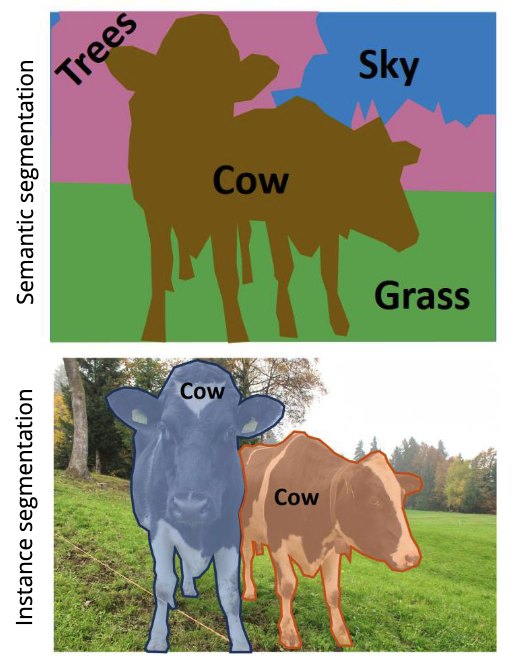
In instance segmentation, we want to detect all objects in an image and identify the pixels that belong to each object.
What might the intuitive approach be here, and what typically happens in practice?
- Intuitive approach:
- Detect objects
- Predict a segmentation mask for each object
- In practice:
- Add another branch to an existing classification / bounding box regression model that outputs a segmentation mask for that region
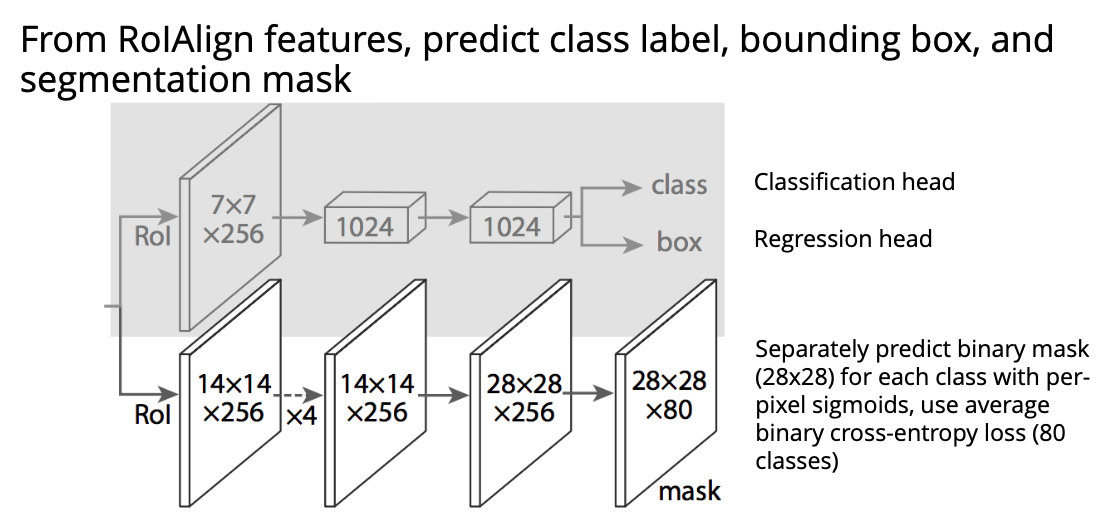
How does RoIAlign improve over RoIPool?
RoIPool uses nearest neighbour quantisation to fill the fixed dimensional representation, RoIAlign instead uses bilinear interpolation of the feature map.
@Visualise the architecture of Mask R-CNN used for instance segmentation.
@Define the problem of panoptic segmentation.
Combine semantic segmentation for stuff with instance segmentation of things.
How does the keypoint problem differ from instance segmentation.
Instead of predicting a mask, you instead predict an object-specific landmark such as joints.
@Visualise what the keypoint masks for human pose estimation might look like, and @describe how this links to instance segmentation.
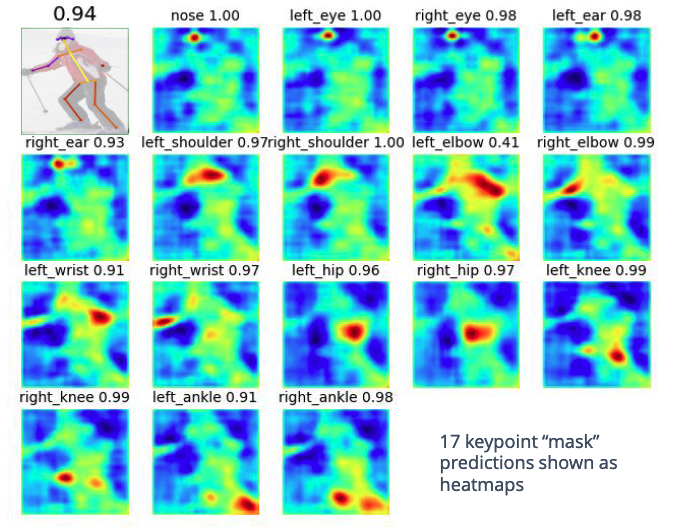
In instance segmentation, we would just predict a mask for the object. Here we predict a heatmap instead, and then convert the heatmap into a keypoint using e.g. a weighted sum over heatmap locations.
Suppose we have some heatmap $h$ corresponding to where we think a particular location in an object is:
How can you convert this heatmap into a single point $(p _ x, p _ y)^\top$?
Calculate
\[(p _ x, p _ y)^\top = \sum _ {u, v} \begin{pmatrix}u \\ v\end{pmatrix} H(u, v)\]where $H = \text{softmax}(h)$.
@Visualise the problem of dense captioning. @Describe how you might implement this.
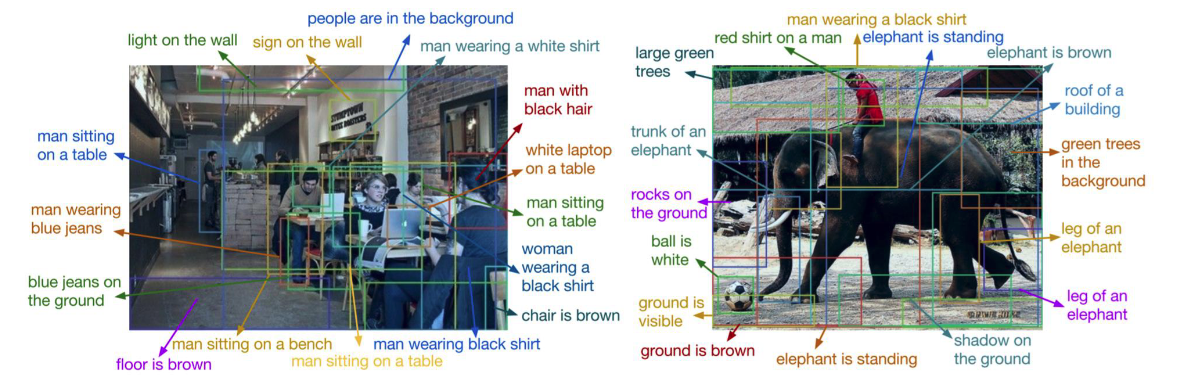
You could add another branch to the model with text output for each region.